Full Stack Data Scientist Responsibilities Across the Data Lifecycle

Written by Emily Hilton
- Why does full-stack matter in today's work?
- The lifecycle stages and core responsibilities
- Practical skills and tooling (what a full-stack data scientist uses)
- Data science best practices for full-stack delivery
- Career implications: roles, paths, and job market realities
- GSDC’s Full Stack Data Scientist Certification
- How to demonstrate capability (portfolio & certification)
- Closing Advice
The role of a full-stack data scientist is no longer a niche: organizations now expect data professionals to span the entire analytics value chain from framing a business question to deploying models and monitoring them in production.
Our guide will walk you through the data lifecycle, clarify data scientist responsibilities at each stage, and share practical data science best practices you can apply to real-world data science projects.
Whether you’re mapping a data pipeline architecture, thinking about machine learning deployment, or planning an analytics career, this guide gives a clear, modern view of how full-stack data science works today.Why does full-stack matter in today's work?
A full-stack data scientist combines statistics, software engineering, and product vision to provide analytics that cover the whole process. They set up data streams, create models, deploy them using reliable machine learning deployment methods, and convert the results into business analytics and insights.
This mix lowers the number of handoffs, accelerates the iteration process, and increases the likelihood that the models will really bring business value. This trend has been noticeable in the recent industry articles and MLOps guides that highlight the importance of unified pipelines and collaboration between different disciplines.
The lifecycle stages and core responsibilities
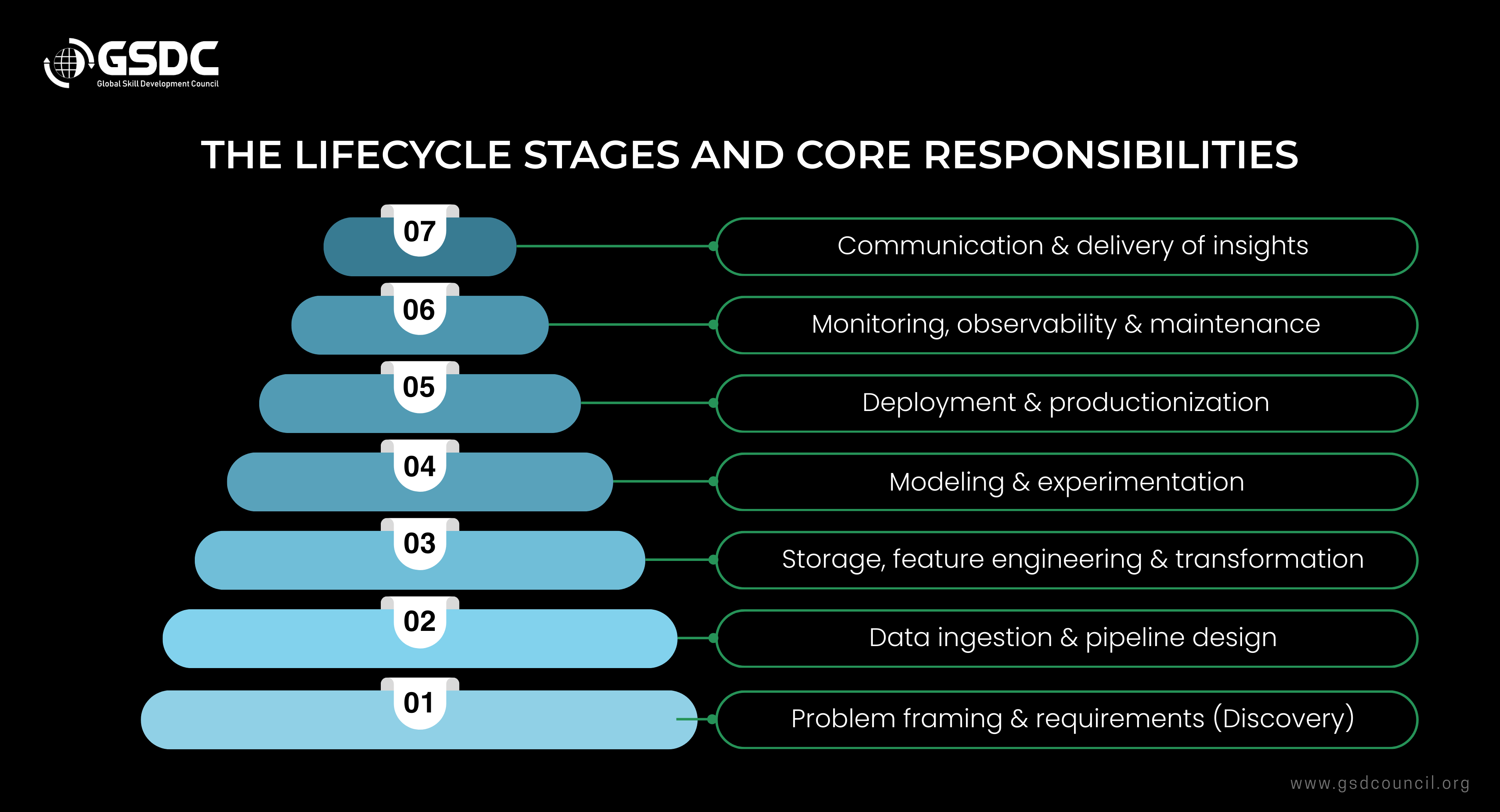
Below, you will get the lifecycle into practical stages and list what a full-stack data scientist typically owns or collaborates on.
1. Problem framing & requirements (Discovery)
Responsibilities:
- Translate a business problem into measurable objectives (KPIs).
- Draft the initial data pipeline architecture needs: sources, throughput, and latency.
- Define success criteria for models and dashboards.
Clear requirements prevent scope creep and make end-to-end analytics outcomes measurable. Many data scientist job description listings emphasize business alignment and requirements skills.
2. Data ingestion & pipeline design
Responsibilities:
- Design and prototype data pipeline architecture (batch vs. streaming, medallion/bronze-silver-gold patterns).
- Build connectors, schedule ingestion jobs, and validate data quality.
- Implement schema evolution and data governance basics.
Modern architectures favor modular pipelines and feature stores to support repeatable model training and machine learning deployment. Reliable pipelines are foundational for any real-world data science project.
3. Storage, feature engineering & transformation
Responsibilities:
- Choose storage formats (data lake, warehouse) and partitioning strategies.
- Create reusable feature engineering code and feature stores.
- Ensure lineage, reproducibility, and data cataloging for discoverability.
The data scientist must balance model needs (fast access to features) with operational constraints (storage costs, latency) as part of a robust data pipeline architecture.
4. Modeling & experimentation
Responsibilities:
- Build candidate models, run experiments, and keep reproducible notebooks/scripts.
- Implement evaluation pipelines and software validation for model performance.
- Use CI for model training and unit tests for data transformations.
Treat modeling like software version code, datasets, and model artifacts so machine learning deployment is predictable and testable. MLOps frameworks formalize this path.
5. Deployment & productionization
Responsibilities:
- Package models (containers, serverless, or model servers) and design A/B or canary rollout strategies.
- Integrate models into the application stack or analytics workflows.
- Collaborate with DevOps/Platform teams to automate machine learning deployment and monitoring.
6. Monitoring, observability & maintenance
Responsibilities:
- Implement telemetry for data drift, model drift, latency, and business KPIs.
- Set alerting and playbooks for incidents; schedule model retraining or rollback plans.
- Manage the maintenance phase of model fixes, re-training, and technical debt mitigation.
Observability is a must: without production telemetry, real-world data science projects deliver blind results.
7. Communication & delivery of insights
Responsibilities:
- Convert model outputs into business analytics and insights with clear visualizations and narratives.
- Build dashboards and reports; present findings to stakeholders.
- Ensure reproducible deliverables so decisions can be revisited.
🛠️ Master the Full Stack Data Scientist Toolkit for data collection, processing, analysis & deployment
Practical skills and tooling (what a full-stack data scientist uses)
A modern full-stack practitioner commonly works with:
- Data orchestration: Airflow, Dagster, or managed services.
- Storage: Cloud data lakes and warehouses (S3/ADLS + Snowflake/BigQuery/Redshift).
- Feature stores & model registries: Feast, MLflow.
- Model serving: KFServing, Seldon, serverless endpoints, or cloud model endpoints.
- Observability: Prometheus, Grafana, EvidentlyAI, or custom dashboards.
Data science best practices for full-stack delivery
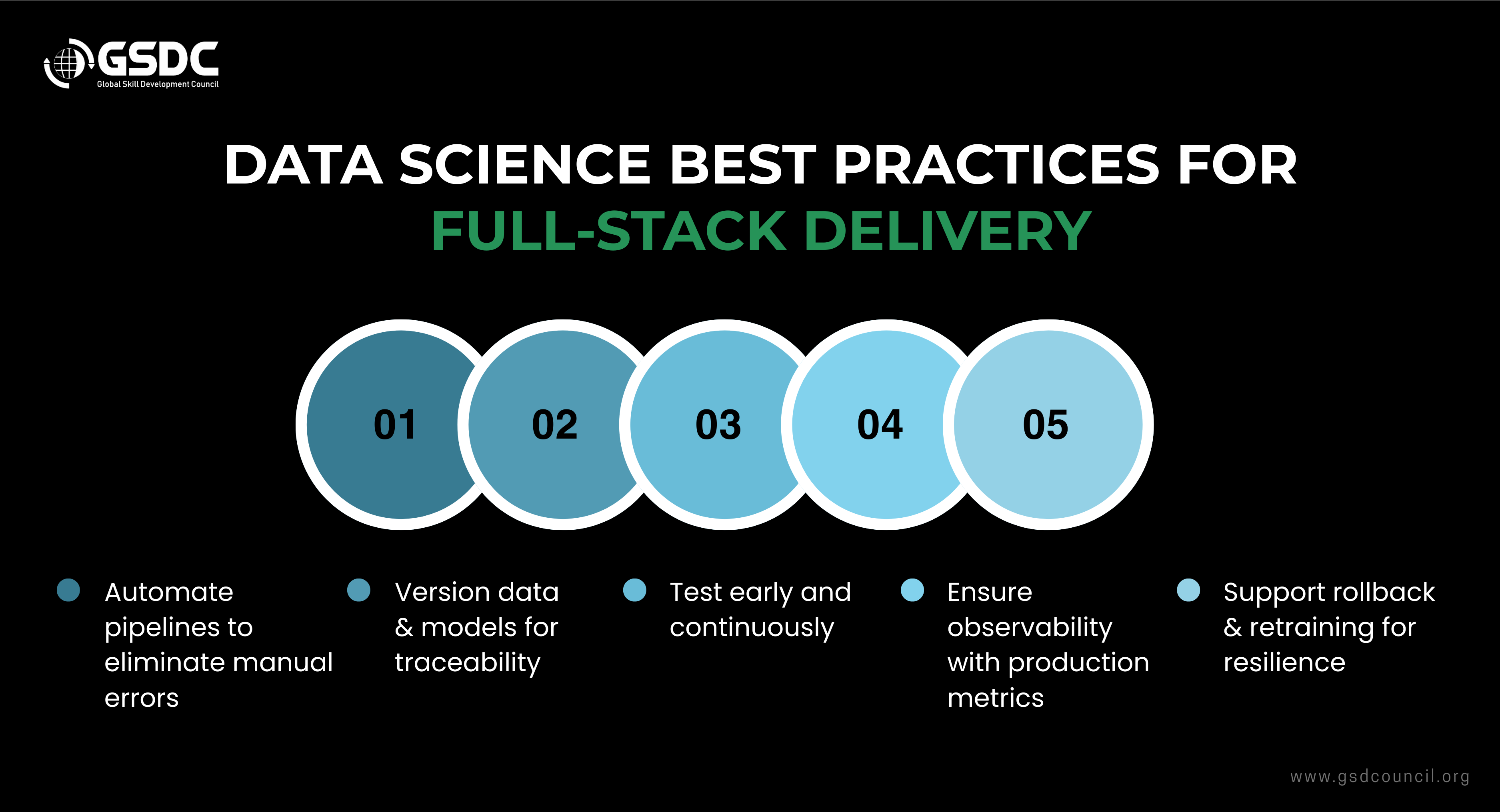
- Automate everything: Ingestion, tests, training, and deployment pipelines to reduce manual errors.
- Treat data and model artifacts as versioned code: For traceability and reproducibility.
- Shift testing left: Valid date data and models early, not after deployment.
- Instrument for observability: Production metrics are non-negotiable.
- Design for rollback and retraining: Resilient machine learning deployment requires safe recovery paths.
These best practices are repeatedly recommended in MLOps roadmaps and enterprise guidance.
Career implications: roles, paths, and job market realities
If you’re wondering if data science is a good career, the short answer is yes for those who combine technical rigour with domain impact. Full-stack roles open diverse data science career path routes: individual contributor (senior data scientist, ML engineer), cross-functional lead (analytics lead, ML product manager), or platform roles (MLOps/feature store owner). Many job postings now list data science roles that expect production experience, not just model notebooks.
- Entry level: Look for internships or data science jobs entry entry-level roles that emphasize data cleaning, basic modeling, and exposure to pipelines.
- Salary: Data science jobs' salary varies by region and seniority; market reports still show competitive pay, with specialized full-stack or MLOps skills commanding premiums.
GSDC’s Full Stack Data Scientist Certification
GSDC’s Full Stack Data Scientist Certification delivers complete training throughout the data lifecycle, encompassing full-stack data science, data pipeline architecture, machine learning deployment, and analytics.
You will engage in real-world projects, create pipelines, train models, and convert data into valuable business insights. Ultimately, you will enhance your technical and analytical skills and remain open to various data science positions, thus paving the way for a fruitful career.

How to demonstrate capability (portfolio & certification)
To show you can run end-to-end analytics, build a portfolio with:
- A documented data pipeline architecture for a real or synthetic dataset.
- A deployed model (e.g., an API endpoint) with monitoring and rollback.
- Clear dashboards that tie model outputs to business analytics and insights.
Closing Advice
Full-stack data science is a matter of owning duties throughout the whole lifecycle of data: creating solid and smart data pipeline architecture, bringing up machine learning deployment processes that are reliable, and turning models into business analytics and insights that are actionable.
If you are mapping out a data science career path, make sure to get practical experience with end-to-end projects, make your work ready for production, and acquire MLOps tools and skills. These skills will change your position from theory to impact. When it comes to hiring, candidates who can describe both model metrics and the pipeline that brings them should be your favorite.

Related Certifications
Stay up-to-date with the latest news, trends, and resources in GSDC
If you like this read then make sure to check out our previous blogs: Cracking Onboarding Challenges: Fresher Success Unveiled
Not sure which certification to pursue? Our advisors will help you decide!










