The SRE Playbook 2025: Engineering Resilience in the Age of AI and Automation

Written by Matthew Hale
- What is an SRE playbook (and how does a playbook work?)
- The four golden signals in the age of AI
- SLOs, error budgets, and governance in AI-enabled environments
- Automation-first reliability patterns, risks, and safety mechanisms
- Organization and culture, cross-functional reliability, and learning from incidents
- Practical playbooks and checklists for 2025
- The evolving role of SREs as reliability custodians
- FAQs;
Reliability is not a luxury in the modern digital era when things are happening extremely fast. It is a differentiator for the business. Introduce the Site Reliability Engineering (SRE) playbook, a formalized collection of practices, tools, and thought processes that increase the quality of how organizations maintain their services available, performant, and safe.
The SRE Playbook 2025: Engineering Resilience in the Age of AI and Automation is presented in this article.
We will take a tour of what a playbook is, its functionality, and create a playbook bit by bit, outlining how AI and automation are transforming the field.
We will incorporate such key terms as SRE Playbook, SRE Playbook example, SRE Playbook Step By Step, how does playbook work, SRE pillars, what does a site reliability engineer do, site reliability engineering tools, site reliability engineer career path, and site reliability engineer learning path, which will be located where needed.
What is an SRE playbook (and how does a playbook work?)

A playbook in the SRE context is a codified set of procedures, guidelines, and decision trees that turn reliability engineering from ad hoc processes into a repeatable practice.
When we ask how the playbook works, we mean: given an incident, a deployment, or a change, the playbook provides clear steps, roles, tools, escalation criteria, automation triggers, and feedback loops.
Consider a SRE playbook example: when latency exceeds threshold X, alerts fire, the four golden signals are evaluated (latency, traffic, errors, saturation), an automated remediation attempt runs, if the error budget is impacted, then human escalation, followed by a post mortem.
The playbook ensures consistency, clarity, and speed.
In 2025, building a modern playbook means integrating AI-powered observability, predictive detection, remediation pipelines, and governance controls. The playbook becomes the living document bridging humans, machines, and processes.
For SRE teams and leaders, it outlines the SRE pillars, the foundational elements such as monitoring/observability, automation/remediation, incident response & post-mortem culture, error budgeting, and organizational collaboration.
The four golden signals in the age of AI
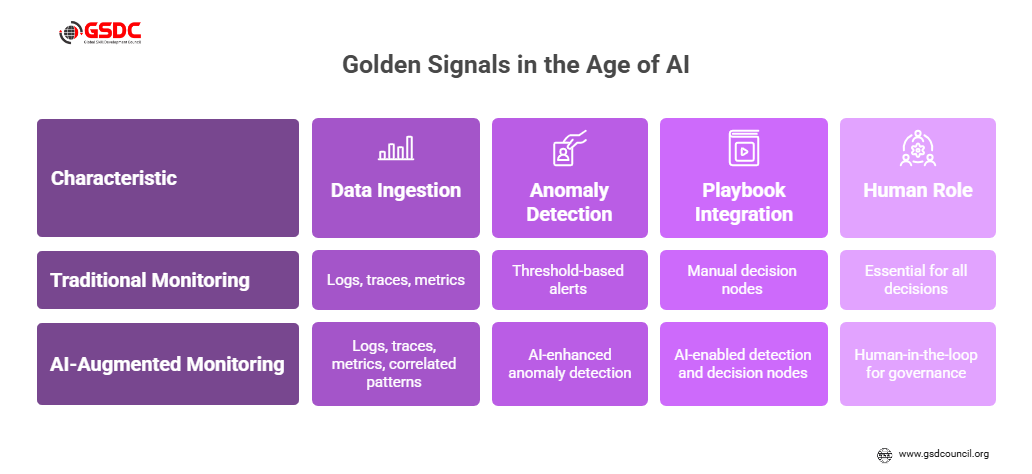
A key part of any SRE practice is monitoring the four golden signals: Latency, Traffic, Errors, and Saturation. These remain essential pillars of reliability. As noted by Google and reiterated in the SRE literature, these signals give a broad brush on system health.
In 2025, with the rise of AI/ML-augmented tooling, these signals gain new depth:
- AI-driven observability ingests logs, traces, and metrics, correlates patterns and anomalies across the golden signal, and more. For example, an AI model may detect saturation anomalies in CPU + memory + queueing combined that wouldn’t have triggered thresholds individually. According to industry commentary, AI/ML in SRE is “fundamentally reshaping how reliability and operational efficiency are achieved.”
- The detection lead-time improves: say the traditional alert might fire after the error rate crosses X. In contrast, AI-enhanced anomaly detection might surface that the error rate is likely to cross X in Y minutes, giving time for pre-emptive mitigation.
- The playbook must now incorporate AI-enabled detection and decision nodes. For example, “If AI anomaly score > threshold and predicted MTTR impact > Z, trigger automated remediation”. That is part of how the SRE playbook works.
- SREs must stay aware of false positives or model drift: the human-in-the-loop remains essential. That’s part of the governance piece.
Example process (SRE Playbook Step By Step)
- Data ingestion from services → logs/metrics/traces.
- Apply the four golden signal monitoring baselines.
- AI engine computes anomaly score + predicted impact (e.g., “latency spike predicted in 10 min”).
- If anomaly and impact threshold both passed → trigger automated remediation job (rollback, scale-up, feature-flag disable).
- If remediation fails or the error budget is impacted → human escalation.
- Post-incident, update thresholds or the AI model feedback loop.
This shows how a playbook integrates the four golden signals and AI-driven observability into a structured workflow.
SLOs, error budgets, and governance in AI-enabled environments
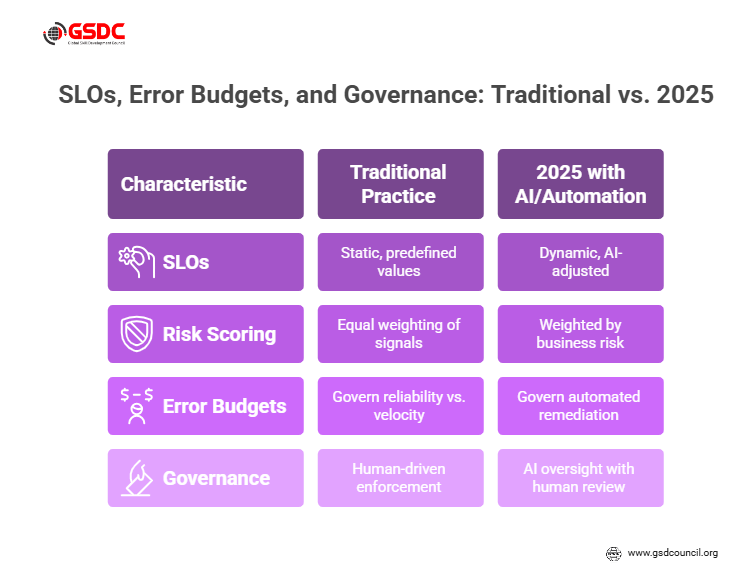
The second core pillar of the playbook is how we define, measure, and govern reliability:
Service Level Indicators (SLIs), Service Level Objectives (SLOs), and error budgets. These are critical in shaping how the SRE team behaves and how they align with business value.
Traditional practice: define a set of SLOs (say 99.9% availability), allocate an error budget (0.1% downtime), monitor SLIs, track error budget consumption, and enforce reliability vs. velocity trade-offs.
In 2025, this framework evolves under AI and automation:
- Dynamic/adaptive SLOs: AI models analyze historical traffic, patterns, system behavior, and recommend SLO adjustments or risk weighting. For example, during high-traffic seasonal events, the model may suggest relaxing the latency SLO slightly or increasing capacity proactively.
- Weighted four golden signals risk scoring: Instead of treating latency/traffic/errors/saturation equally, AI can correlate them to business risk (e.g., errors during checkout vs. errors in a non-core batch job) and adjust alerting and remediation priority accordingly.
- Error budgets gain new roles: In an automation-first world, error budgets govern how much automated remediation or self-healing is allowed. For example, if the error budget is > 50% remaining, you might permit canary deployments with less manual review; once the budget is low, stricter controls engage.
- Governance/trust in automation: Because AI and automated remediation are more present, human oversight is essential. Explainable AI, audit logs, and change-control for automation flows become part of the playbook.
The SRE playbook example for governance in 2025 might include:
- Review AI model thresholds monthly.
- Audit self-healing incidents quarterly.
- If automatic remediation triggers more than three times per month, raise a review ticket.
- Escalation path when SLO violation predicted by AI model with > 80% confidence.
According to Dynatrace’s “State of SRE” insights, 99% of SRE teams reported challenges when defining and creating SLOs. Also, the concept of generative AI and runbook automation is already coming into play.
Thus, a modern SRE playbook must clearly map what a site reliability engineer does in this context:
- Define and monitor SLIs/SLOs/error budgets.
- Interpret AI-driven predictions and decide when to automate.
- Participate in the governance of automation flows.
- Post-incident triangulation of business impact and SLO compliance.
Download the AI-Driven Reliability Checklist to:
Automation-first reliability patterns, risks, and safety mechanisms
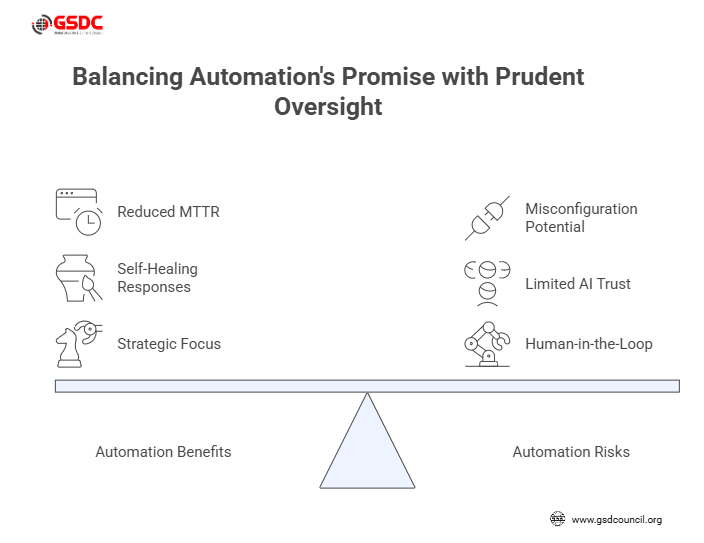
One of the most transformative shifts in 2025 is automation. The playbook must explicitly incorporate automated remediation and self-healing patterns.
Automation and remediation playbooks
When we ask how does playbook works in this context, the playbook codifies which workflows are safe to automate, under what conditions, what human approvals are required, and how rollback happens.
Here’s how it might look in a SRE Playbook Step By Step format:
- Trigger: AI anomaly or threshold breach.
- Decision node: If automated remediation safe flag = true AND error budget > threshold AND human review not required → go to step 3; else escalate.
- Automated remediation: e.g., rollback deployment, disable feature flag, scale service cluster.
- Validate remediation: monitor SLIs for 5 minutes, if within thresholds → mark resolved; else escalate.
- Post-incident: record automation event, review in post-mortem, update playbook if needed.
Automation patterns include: rollbacks, feature-flag toggles, staged rollouts, and self-healing responses (e.g., auto-restart service). Teams adopting large-scale cloud-native architectures report that automated remediation significantly reduced Mean Time To Repair (MTTR).
For example, one paper described autonomous multi-agent systems for reliably handling cloud-scale failures.
Automated change-impact analysis tools, like Site Reliability Guardian (by Dynatrace), validate deployments against SLOs automatically.
Risks and safety mechanisms
Automation carries risk: misconfiguration, runaway remediation, and limited trust in AI. The playbook must address:
- Idempotence: ensure automation flows can run safely multiple times without unintended side effects.
- Safety constraints: e.g., do not auto-remediate during major holiday traffic spike unless human override.
- Rollback plans: every automated action must include a safe rollback path.
- Human-in-the-loop governance: critical remediation is still approved or audited by SREs.
- Audit logs and explainability: when an AI decision triggers remediation, we must record why, how, and what.
- Escape hatch: ability to abort automatic flow and revert to manual mode.
When automation is embedded into the SRE playbook, SREs shift from doing manual toil to overseeing the automation, refining playbook logic, and focusing on strategic reliability engineering.
Organization and culture, cross-functional reliability, and learning from incidents
Technical tools and playbooks matter, but they’re only as strong as the organization and culture that deliver against them.
One of the fundamental pillars is the people and process dimension: building resilient teams, enabling cross-functional collaboration, and learning from failures.
The role of the SRE and the career path
If you’re wondering what a site reliability engineer does or exploring the site reliability engineer career path, this section is for you.
An SRE’s role is hybrid: they combine software engineering, infrastructure/ops, automation, metrics-driven decision-making, and often organizational influence.
Typical SRE career path:
- Junior SRE: focuses on monitoring, alerts, and basic remediation workflows.
- Mid-level SRE: builds automation pipelines, defines SLOs, supports deployment safety.
- Senior SRE (or Reliability Engineering Lead): owns reliability strategy, mentors SREs, designs the SRE playbook, and works cross-functionally with security, product, and Dev teams.
- Director/Head of Reliability: sets organizational reliability goals, invests in tooling, culture, and coordinates across product, security, and operations.
A strong site reliability engineer learning path includes: foundations in software engineering + infrastructure, observability tooling, SRE metrics and practices, automation frameworks, AI/ML awareness, incident response/post-mortem culture, and communication/collaboration skills.
Organizational trends in 2025
The organizational structure of SRE teams is evolving:
- SRE teams are embedded earlier in the software development lifecycle rather than just operations.
- Reliability is shared across Dev, QA, SRE, Security, and Risk teams rather than siloed. The “Dev vs Ops” divide continues to diminish.
- Blameless post-mortems expand to include failures of AI/automation tooling and data-quality issues (not just service downtime).
- Regular resilience drills, chaos engineering, and capacity planning with AI-predicted traffic spikes become mainstream. One commentary noted: “AI-aware load balancers … are emerging to manage workloads seamlessly across data centers.”
Culture change strategies
To embed the playbook into culture:
- Train SREs and Dev teams on AI/MLOps fundamentals, observability tooling, and automation safety.
- Conduct table-top incident simulations that include automation flows failing or AI misprediction.
- Maintain cross-functional alignment: product prioritization, reliability engineering, security, and business leadership must agree.
- Use insights from post-mortems to update the playbook iteratively.
- Incentivize reliability mindsets: not only feature delivery velocity but also reliability metrics, error-budget health, and automation coverage.
Practical playbooks and checklists for 2025
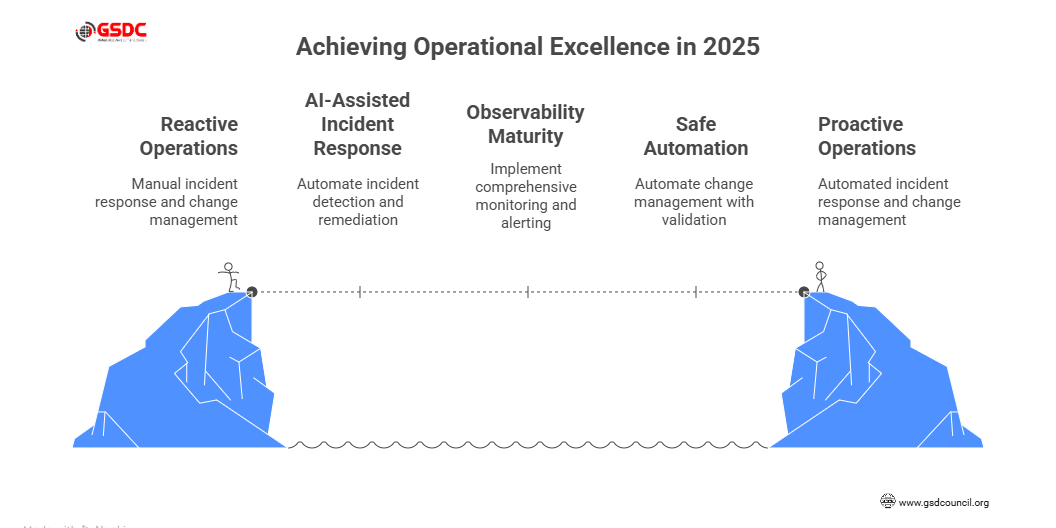
Now we get to the actionable part. Below are three tangible playbook checklists you can adopt and tailor to your organization. These are built around the themes we’ve discussed: observability, incident response & remediation, and change-management automation.
Playbook A: AI-assisted incident response
Trigger detection
- AI anomaly score > threshold OR SLI breach.
- Error budget consumption rate > X% per week.
Triage & decision
- Automation eligibility: Is the error budget sufficient AND the scenario covered in the playbook?
- If yes → trigger automated remediation.
- If no → human escalation.
Automated remediation
- If yes → trigger automated remediation.
- Execute rollback/scale-up/feature toggle pipeline.
- Monitor SLIs for immediate response.
Escalation & manual intervention
- If remediation fails or user impact persists → SRE-on-call notified, shift to manual.
Post-incident review
- Blameless review of triggers, AI prediction vs outcome, automation success/failure.
- Update playbook steps, thresholds, and automation logic.
Playbook B: Observability-maturity checklist
- Inventory service endpoints & dependencies; map data lineage.
- Ingest logs, metrics, and traces from all service components (microservices, containers, data pipelines).
- Implement four golden signals (latency, traffic, errors, saturation) across services.
- Deploy AI/ML anomaly-detection tooling: ingest historical data, train baseline models, and set anomaly thresholds.
- Enable dynamic/adaptive SLO recommendation engine.
- Define alerting and automated remediation eligibility.
- Embed audit logs, automation decision tracing, and human-in-the-loop gates.
Playbook C: Change-management & safe automation
- For each deployment/change: run pre-deployment validation (canary, feature-flag, change impact).
- Tools like Site Reliability Guardian validate SLOs automatically.
- Tools like Site Reliability Guardian validate SLOs automatically.
- Tag whether the automation flow is eligible for auto-remediation (yes/no).
- Define rollback criteria: if SLO deviates by > X% or anomaly score > Y.
- Maintain a “safe zone” error budget threshold: if remaining budget < Z%, restrict auto-remediation, require human approval.
- Post-deployment: monitor for 30 minutes, validate SLIs, update change-management log.
- Monthly audit: count automation triggers, failures, remediation success rate, update playbook.
Benchmarks & metrics
- According to recent research, AI/ML-driven observability and remediation can reduce Mean Time To Detect (MTTD) and Mean Time To Repair (MTTR). For example, autonomous systems for cloud reliability improved the failure mitigation success rate by ~1.5×.
- Surveys show 88% of SREs believe their role’s strategic importance has increased, and by 2025, about 85% of teams aim to standardize on a unified observability platform.
- Organizations that adopt structured SRE playbooks report fewer SLA violations and tighter error-budget consumption (though exact figures vary).
These checklists form the SRE playbook example you can adapt. They represent concrete steps toward embedding reliability, automation, and AI into your operational fabric.
Advance your career with the GSDC SRE Foundation Certification, your next step toward mastering reliability in the age of AI and automation.

The evolving role of SREs as reliability custodians
To conclude, we can place this in the context of what this implies to the SRE playbook, the SRE engineer, and your organization.
By 2025, the SRE field will not only be a matter of extinguishing fires anymore, but it will be a matter of creating resiliency as a product capability. The contemporary SRE engineer applies software engineering to automate the infrastructure, implement intelligent observability, use adaptive SLOs, and automate remediation.
They are the ones to define the career path of the site reliability engineer as they proceed to design reliability systems, as opposed to firefighting.
The SRE playbook has been positioned at the junction between people and tools, and automation. It documents not only when something is wrong, do this, but also how does playbook works when the AI predicts an outage, the automation causes a rollback, and the business impact is reduced before users can complain.
To any individual undertaking the learning journey of a site reliability engineer, understanding these concepts, observability, automation, SLO governance, and AI in ops will mark the future of your life. When working with teams that switch to an SRE playbook step by step, make things simple: map your four golden signals, create one automation flow, codify, measure, and repeat.
Reliability is no longer a by-product or feature in the age of AI and automation; it is a design choice, and is engineered, measured, and controlled. Your blueprint is your playbook. Use it well.
FAQs;
1. What is an SRE Playbook, and why is it important in 2025?
An SRE Playbook is a structured guide that outlines processes, tools, and best practices for managing system reliability. In 2025, it’s essential because AI and automation are redefining how teams detect, prevent, and respond to incidents, turning reliability into a proactive discipline.
2. How does AI improve Site Reliability Engineering?
AI enhances observability, predicts outages, and automates remediation. This reduces manual toil, shortens Mean Time to Repair (MTTR), and helps teams maintain Service Level Objectives (SLOs) with greater accuracy.
3. What are the key pillars of SRE in the age of automation?
The main SRE pillars include observability, automation, incident response, error budgeting, and continuous learning. In 2025, AI-driven monitoring and adaptive SLOs are becoming core parts of these pillars.
4. How can I start my Site Reliability Engineering career?
Start by learning DevOps fundamentals, monitoring tools, and automation frameworks. Then, boost your credentials with the GSDC SRE Foundation Certification to gain practical skills and stand out in a competitive field.

Related Certifications
Stay up-to-date with the latest news, trends, and resources in GSDC
If you like this read then make sure to check out our previous blogs: Cracking Onboarding Challenges: Fresher Success Unveiled
Not sure which certification to pursue? Our advisors will help you decide!










