Why Systems Fail: Site Reliability Engineering Beginner Guide

Written by Matthew Hale
- What is Site Reliability Engineering?
- Why Site Reliability Engineering is Important
- The Core of SRE: SLIs, SLOs, and Error Budgets
- Key Metrics for Site Reliability Engineering
- Site Reliability Engineering Best Practices
- Site Reliability Engineer Key Skills
- How to Learn Site Reliability Engineering
- Site Reliability Engineer Salary and Career Growth
- Develop a practical way in SRE with certification
- Final Thoughts
Site Reliability Engineering is becoming essential as businesses depend more on digital systems.
Today, even a small system failure can affect users and impact revenue. A payment app not working or a slow website can quickly lead to frustration and loss of trust.
In fact, over 90% of organizations have faced at least one outage in recent years, showing how common these issues are.
This is why companies are focusing on Site Reliability Engineering to build systems that stay reliable even when things go wrong.
In this site reliability engineering beginner guide, we’ll explain how SRE works, why it matters, key metrics, and how you can build a strong site reliability engineering career.
What is Site Reliability Engineering?
Let’s start with a simple question: what is site reliability engineer role?
Site Reliability Engineering is about using engineering methods to manage and run systems.
Instead of fixing issues manually, SRE focuses on building systems that are automated, scalable, and reliable from the start.
A site reliability engineer works to keep systems running smoothly, monitor performance, fix issues quickly, and improve stability over time.
This approach is based on reliability engineering principles, where systems are designed to handle failures and recover quickly.

Why Site Reliability Engineering is Important
Understanding why site reliability engineering is important comes from how systems are used today.
People expect applications and websites to always be available. Even the smallest problem can cause them to have a bad experience. Additionally, the systems are constantly growing and changing, which makes them harder to manage.
This is where Site Reliability Engineering becomes important because it can help teams:
- Ensure the smooth operation of the system.
- Minimize system downtime.
- Improve the user experience.
- Manage complex systems more easily.
This is the reason why companies are focusing more on SRE to develop systems that are always reliable and can scale with the business.
The Core of SRE: SLIs, SLOs, and Error Budgets
SRE is not only about fixing things, but it is also about measuring how reliable a system is. These measurements are known as Site Reliability Engineering Metrics.
Service Level Indicators (SLIs)
SLIs are used for measuring how a system is actually performing. This includes things such as how quickly it responds, how available it is, or how many errors it has.
For example, how quickly a page is loading or how many successful transactions are being made.
Service Level Objectives (SLOs)
SLOs are used for defining how a system should perform.
This includes things such as being available 99.9% of the time or responding in 2 seconds.
Error Budgets
An error budget is used for defining how much failure is acceptable in a certain period of time.
This includes things such as being available 99.9%, which means a certain amount of downtime is acceptable.
This enables teams to:
- Move faster with new changes.
- Release features more confidently.
- Maintain system reliability.
These three elements, SLIs, SLOs, and error budgets, work together in such a way that teams can make better decisions and be successful in maintaining reliability, especially as the system grows.
Understanding these concepts is also an important step if you are planning to explore an SRE Foundation Certificate.
Key Metrics for Site Reliability Engineering
The key metrics are what make SRE effective. The metrics may be basic or more complex as required by more advanced systems.
The key metrics that are used in site reliability engineering are:
Site Reliability Engineering Metric | Simple Meaning |
Service Level Indicators (SLIs) | Measure how the system is performing, like latency or availability. |
Service Level Objectives (SLOs) | Define the target performance, such as 99.9% uptime. |
Service Level Agreements (SLAs) | Set the agreed performance level between the provider and users. |
Availability | Shows how often the system is up and running. |
Latency | Measures how fast the system responds. |
Error Rate | Tracks how often requests fail. |
Throughput | Shows how many requests the system handles. |
Mean Time to Recovery (MTTR) | Shows how quickly the system recovers after a failure. |
Mean Time To Detect (MTTD) | Shows how quickly issues are detected. |
Change Failure Rate | Shows how often system changes cause failures. |
These Site Reliability Engineering Metrics are used to monitor how long it takes to encounter a failure after a change has been made to the system.
Site Reliability Engineering Best Practices
To achieve reliability, successful teams implement a set of site reliability engineering best practices.
These practices are effective in ensuring that the system remains reliable despite the increased complexity.
The key practices include:
Automating repetitive tasks:
This ensures that the team does not waste time on tasks that are not useful.
Establishing SLIs and SLOs
This ensures that the team can measure the system and determine whether it is performing as expected.
Using Error Budgets
This ensures that the team can determine when it is appropriate to deploy new updates without affecting reliability.
Monitoring and Alerting
This ensures that the team can quickly detect problems.
Reviewing Incidents
This ensures that the team can determine the cause of the problem and prevent it in the future.
Building Scalable Systems
This ensures that the system can handle increased demand and automatically recover in case of problems.
These are the key concepts that are often discussed in programs offered by the Global Skill Development Council, ensuring that individuals understand how these practices are used in the real world.
Site Reliability Engineer Key Skills
To become a successful site reliability engineer, you need the right combination of technical skills and problem-solving skills.
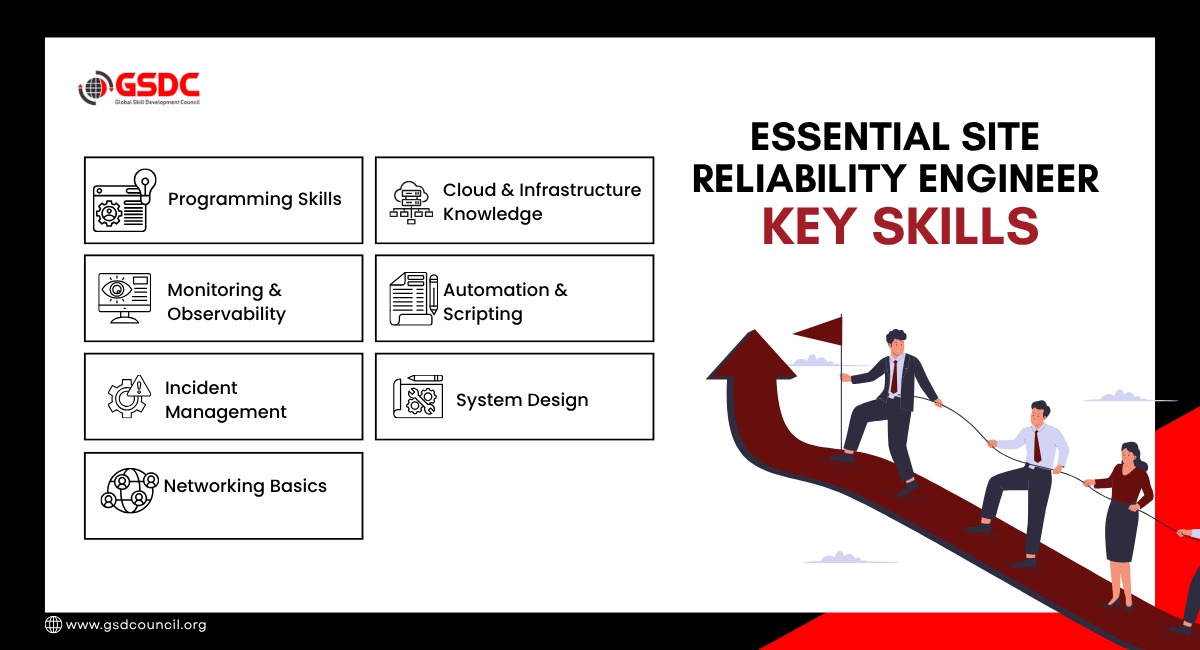
These skills are critical for building a strong site reliability engineering career.
How to Learn Site Reliability Engineering
If you're wondering how to learn site reliability engineering, the path is more practical than theoretical.
A step-by-step guide on how to learn site reliability engineering:
Step 1: Begin with a site reliability engineering book.
This will give you a basic understanding of the concepts.
Step 2: Learn Linux, networking, and system fundamentals.
This is the basics of how things work.
Step 3: Learn cloud platforms and DevOps tools.
Most systems are built on the cloud and run on automation tools.
Step 4: Learn site reliability engineering with a workbook.
This is the practical application of what you learned.
Step 5: Learn site reliability engineering by doing projects.
Try monitoring, automation, and incident handling.
Step 6: Learn site reliability engineering with a certification.
This helps validate your skills and improve career opportunities.
The key is to keep practicing. SRE is learned by doing, not just reading.
Site Reliability Engineer Salary and Career Growth
One of the most searched questions is: how much does a site reliability engineer make?
The salary of a site reliability engineer varies according to experience, skills, and location.
- Entry-level roles can start around ₹5–10 LPA.
- Mid-level professionals can earn between ₹10–25 LPA.
- Senior roles can go beyond ₹30 LPA.
On average, a site reliability engineer salary in India is around ₹15–20 LPA. For those in the US, the pay scale may be larger.
As the requirement for reliable systems increases, the career growth in the field of site reliability engineering is also high.
Organizations are in need of skilled employees in the field of site reliability engineering.
Develop a practical way in SRE with certification
While you need to understand the concepts if you are aiming for a career in site reliability engineering, it is not enough on its own.
This is because, in site reliability engineering, you are dealing with actual systems and actual problems, and it is not all about theory.
This is where a site reliability engineering certification comes in, especially if you are aiming for a career in site reliability engineering.
The programs offered by the Global Skill Development Council (GSDC) are focused on actual skills, such as monitoring, automation, service level indicators, and incident management, and show you how site reliability engineering works in actual scenarios, especially for those aiming for a career in site reliability engineering.

Final Thoughts
Site Reliability Engineering goes beyond the mere technical aspects; it also represents a transformation in the way systems are handled.
It's a shift from reacting to failures to preventing them, from manual processes to automated processes, and from guesswork to reliable processes.
Whether you're learning more about Site Reliability Engineering Metrics or applying best practices, SRE is changing the way systems are built and operated today.
If you're looking for a career that combines engineering, problem-solving, and real-world impact, a site reliability engineering path may be one of the most future-proof options you could choose.

Related Certifications
Frequently Asked Questions
Stay up-to-date with the latest news, trends, and resources in GSDC
If you like this read then make sure to check out our previous blogs: Cracking Onboarding Challenges: Fresher Success Unveiled
Not sure which certification to pursue? Our advisors will help you decide!




